Changelog
April 29, 2025
Summary:
- New image generation capabilities with three powerful models (GPT-Image, Gemini Flash Experimental, Imagen 3)
- Faster and more cost-effective Llama 4 Maverick and Scout models.
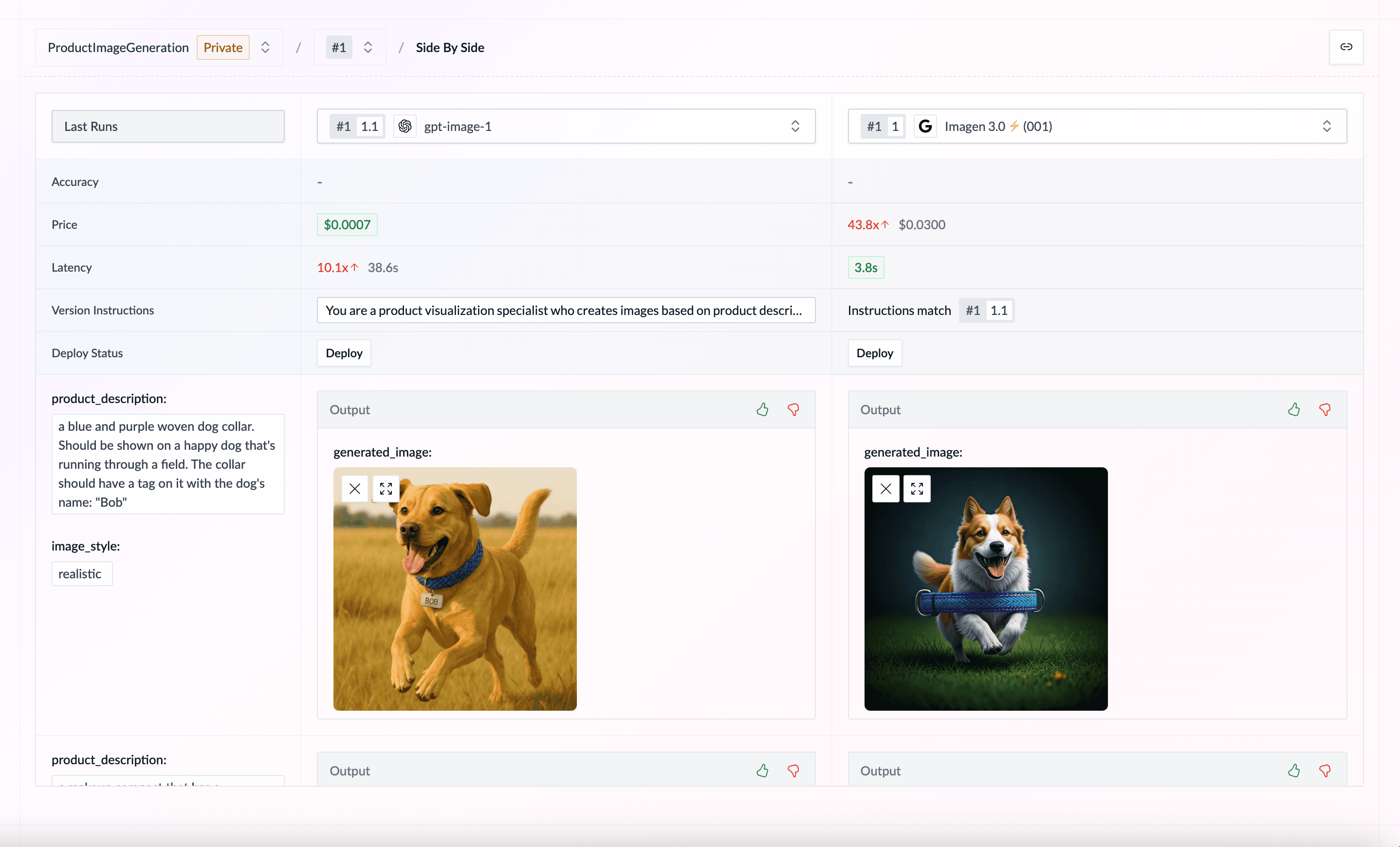
Generate Stunning Visuals with Cutting-Edge Image Models
WorkflowAI now empowers you to generate images directly within the platform, opening up a world of creative possibilities. Access the same powerful technology that took the internet by storm, with viral trends like the Studio Ghibli-style transformations that allowed users to "Ghiblify" their photos and memes. This capability underscores WorkflowAI's commitment to providing access to state-of-the-art AI models, all in one place, without the complexity of managing multiple integrations.
We're introducing three new models to kickstart your image generation journey:
- GPT-Image from OpenAI: This versatile model, the same one powering ChatGPT's image generation, excels at creating images across diverse styles, faithfully following custom guidelines, leveraging world knowledge, and accurately rendering text. Pricing is $5 per 1M text input tokens, $10 per 1M image input tokens, and $40 per 1M image output tokens, translating to roughly $0.02 to $0.19 per generated image depending on quality.
- Gemini 2.0 Flash Experimental: Generate text and inline images conversationally with Gemini. Edit images or create outputs with interwoven text, like blog posts with integrated visuals. This experimental model is currently free to use, allowing you to explore its capabilities without cost. Note that all generated images include a SynthID watermark.
- Imagen 3: Generate images with exceptional detail, rich lighting, and fewer artifacts. Imagen 3 understands prompts written in natural language, generates images in various formats and styles, and renders text effectively. At just $0.04 per image, Imagen 3 offers a cost-effective solution for high-quality image generation.
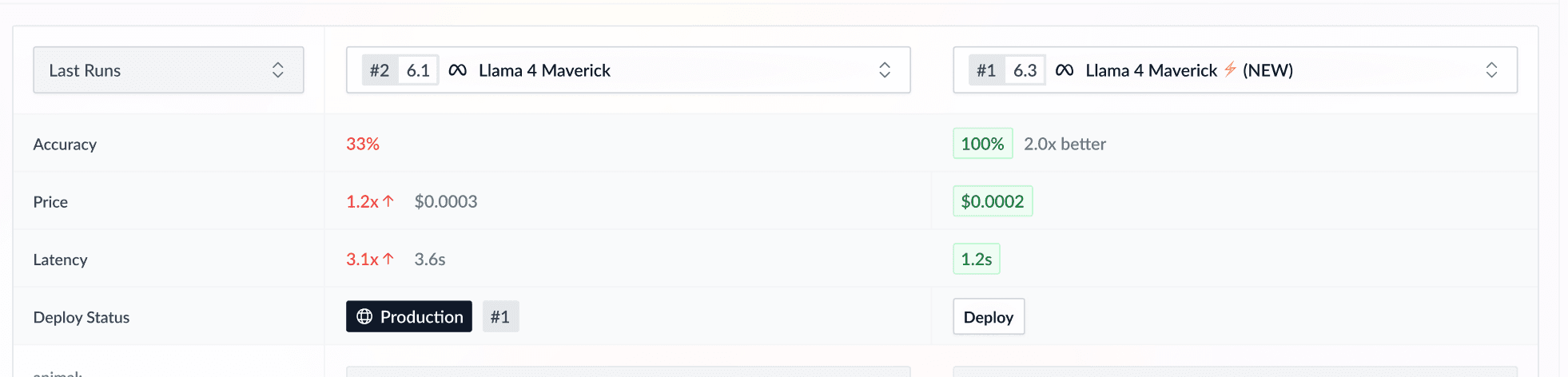
Enhanced Llama Models for Optimal Performance
We've updated our Llama models to provide you with even better performance and value. The new Llama 4 Maverick and Llama 4 Scout models are cheaper and faster than the original versions we support, ensuring you get the most out of your AI workflows. You can differentiate the new models by the presence of a ⚡️ icon after their name in the playground. This update reflects WorkflowAI's dedication to benchmarking accuracy, speed, and cost, helping you select the best model with confidence.
April 24, 2025
Introducing Gemini 2.5 Flash: Expanding Our Model Ecosystem
At WorkflowAI, we're committed to providing access to the world's top AI models in one place. Today, we're excited to add Google's Gemini 2.5 Flash to our growing collection of state-of-the-art models. This addition reinforces our mission to bring you the best models from every provider—OpenAI, Anthropic, Google, Llama, Grok, and DeepSeek—all in one unified platform with zero setup required.
Gemini 2.5 Flash offers an exceptional performance-to-cost ratio, placing it on the efficiency frontier. As a fully hybrid reasoning model, it allows you to toggle thinking capabilities on or off (in WorkflowAI, we have two separate models - one with thinking on, one without).
Pricing:
- Input tokens: $0.15/1M tokens (50% increase from Gemini 2.0 Flash)
- Non-thinking output tokens: $0.60/1M tokens (50% increase)
- Thinking output tokens: $3.50/1M tokens (775% increase)
Performance: Google's benchmarks show Gemini 2.5 Flash outperforming its predecessor in nearly every category, including reasoning, mathematics, and code generation—all accessible through WorkflowAI's simple, unified API.
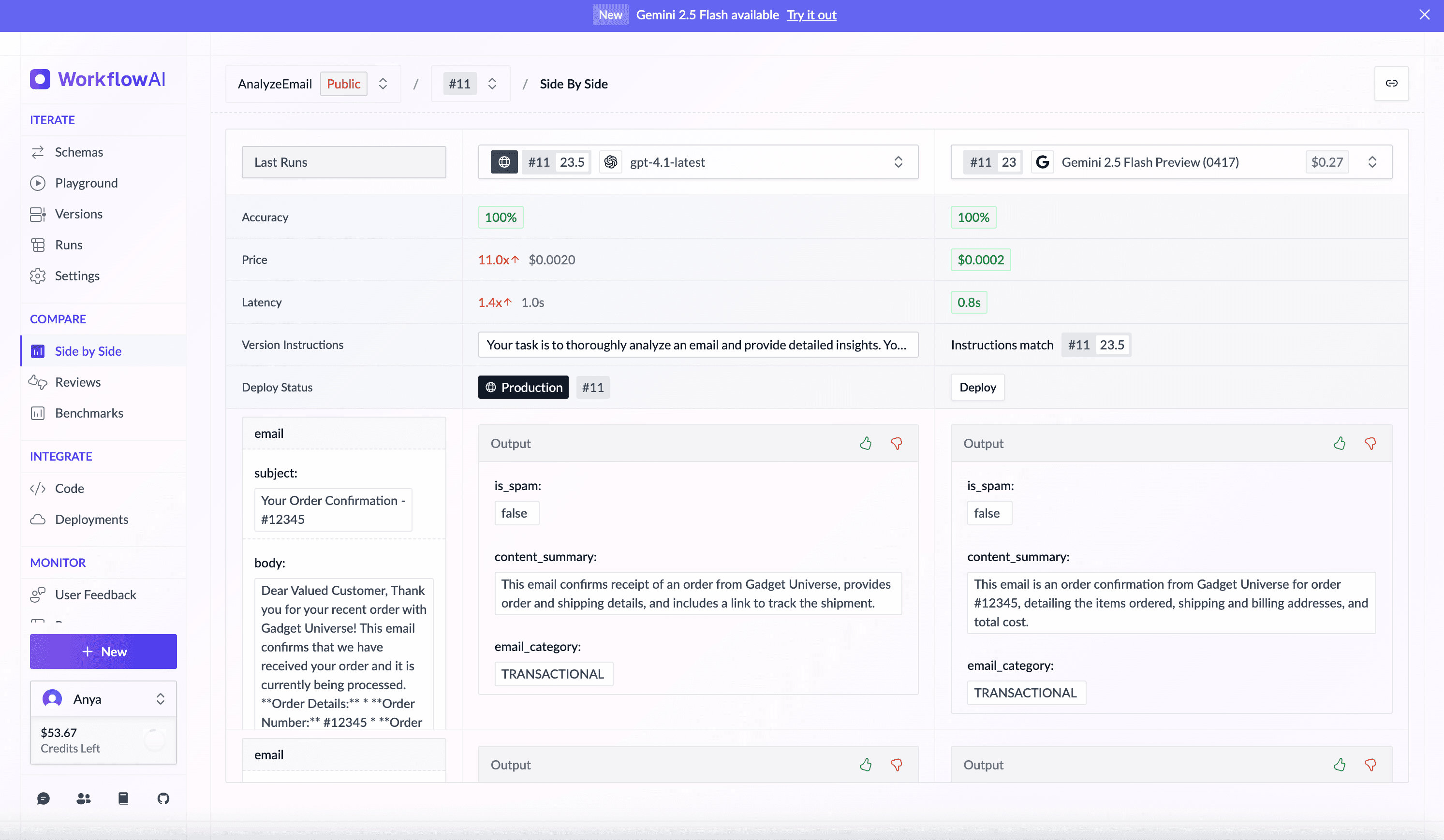
New Side-by-Side Comparison: Make Confident Model Decisions
No more switching between tabs and spreadsheets to compare models! WorkflowAI's new side-by-side view empowers you to directly compare any two models, helping you evaluate quality, cost, and speed to make data-driven decisions for your AI features.
Wondering how Gemini 2.5 Flash performs against your current model? Simply navigate to the Side by Side page under the COMPARE section of any agent, and select Gemini 2.5 Flash—or any other model you're curious about—from the righthand column. This feature embodies our commitment to helping you find the best model for your specific use case, validating your AI decisions with real, comparable outputs.
How is this guide?